Advertisers seeking accurate ROAS should use large-scale, randomized geo tests

Multi-armed Cluster Randomized Trial design using DMAs for national ad campaign
The smallest Fortune 500 companies have revenue on the order of $10 billion, meaning they are likely spending at least $1 billion on paid advertising. If your company is spending hundreds of millions on advertising, there is no excuse for optimizing ROI with half measures. Yet that is exactly what most companies do, relying on subpar techniques such as attribution modeling, matched market tests, synthetic control methods and other quasi-experimental approaches.
Quasi-experiments, by definition, lack random assignment to treatment or control conditions. The first rule of quasi-experiments, as the methodological literature consistently makes clear, is that they should be used when randomized controlled trials (RCTs) are "infeasible or unethical."
As Athey and Imbens (2017) state: "The gold standard for drawing inferences about the effect of a policy is a randomized controlled experiment. However, in many cases, experiments remain difficult or impossible to implement, for financial, political, or ethical reasons, or because the population of interest is too small."
For advertising measurement, it's rarely unethical to run an RCT, and it's almost always feasible. Decisions to opt for lesser standards, say the bronze or tin of quasi-experiments or attribution, usually stem from a lack of understanding of how significantly inferior those methods are for causal inference compared to RCTs, or misplaced priorities about the perceived cost of high-quality experiments.
As for the general accuracy of quasi-experimental methods, many practitioners assume they provide at least "directionally" correct results, but in reality such results can often be misleading or inaccurate to a degree that's difficult to quantify without benchmark randomized trials.
The seminal paper "Close Enough? A Large-Scale Exploration of Non-Experimental Approaches to Advertising Measurement" (Gordon et al., 2022) demonstrated this. It took some 600 Facebook RCT studies and reanalyzed their results using double/debiased machine learning (DML) and stratified propensity score matching (SPSM), among the most popular forms of quasi-experiments, the types used by many panel-based ad measurement companies. In keeping with the journalistic adage that the answer to any headline posed as a question is “no,” the researchers found the quasi-experimental approaches were "unable to reliably estimate an ad campaign's causal effect."
Regarding the perceived cost of large-scale experiments: The primary cost to advertisers isn't in conducting rigorous RCTs, but rather in the ongoing inefficiency of misallocated media spend. For companies investing hundreds of millions annually in advertising, the opportunity cost of suboptimal allocation—both in wasted dollars and unrealized sales potential—can substantially outweigh the investment required for proper experimental design.
Witness Netflix, which, almost 10 years ago, assembled a Manhattan Project of foremost experts in incrementality experimentation. Their cumulative RCT findings led them to eliminate all paid search advertising. This counterintuitive but data-driven decision would likely never emerge from attribution modeling or quasi-experimental methods alone, highlighting the unique value proposition of rigorous experimental practice.
In terms of the best type of experiments for advertising effect, there has been a growing consensus among practitioners that geographic units are more reliable today than user, device or household units. For years, the myth of the internet's one-to-one targeting abilities gave rise to the belief that granular precision was synonymous with accuracy. While this was never really true, the rise of privacy concerns and the deterioration of granular units of addressability now mean that user-level experiments are less accurate than tests based on geographic units such as designated market areas (DMAs). The irony is that identity is not necessary for deterministic measurement.
Beyond privacy problems and the need for costly technology and intermediaries in the form of device graph vendors and clean rooms, the match rates of user-level units between the media where they run and the outcome data, e.g., sales, of the dependent variable are usually too weak for experimentation, e.g., below 80%. Even at higher match rates, measuring accurately for typical ad sales effects of around 5% or less is unachievable due to spillover, contamination and statistical power considerations.
Postal codes would be an ideal experiment unit, given that they number in the thousands in most countries, a level of granularity that fortifies the distribution of unobserved confounding variables and is a large enough base of units to measure small effect sizes. But, as I argued in an AdExchanger article a few months ago, publishers seem unwilling to make the necessary targeting reforms to make them a viable experimental unit to fix the morass of digital advertising measurement.
That leaves DMAs, which thankfully work well in the large US market as an experiment unit for national advertisers willing to run large-scale tests with them. Geographic experiments broadly fall into a class of RCT known as cluster randomized trials (CRT), where the human subjects of the ad campaigns are clustered by regions. A key benefit of geo experiments is that they correspond to ZIP codes already in the transactional data in many advertisers' first-party CRM databases and third-party panels, enabling researchers to read the lift effect without any data transfer, device graphs, clean rooms or privacy implications. And, importantly, no modeling required.
Although there are only 210 DMAs in the US, and they vary widely by population size and other factors, collectively they represent a population of roughly 350 million people. Randomization is the most effective way to control for biases and unknown confounders among those varying factors and deliver internal validity to test and control group assignments.
A parallel CRT, with one test and one equal sized control group based on all 210 DMAs, is the most statistically powerful kind of design, especially appropriate for testing a medium not currently or regularly in an advertiser's portfolio.
For a suppression test, where the marketer seeks to validate or calibrate the effect size of a medium where its default status is always-on advertising in a given channel, such as television or search, a stepped CRT design, where ads are turned off sequentially across a multi-armed experiment, is a good option. The stepped approach allows the advertiser to ease into a turn-off test and monitor sales, such that the test can be halted if the impact is severe. They also require less than 50% of media weight to be treated, albeit at the sacrifice of statistical power: the illustration here shows a design using multiple test and control arms that put only 18% of the total media weight into cessation treatment.
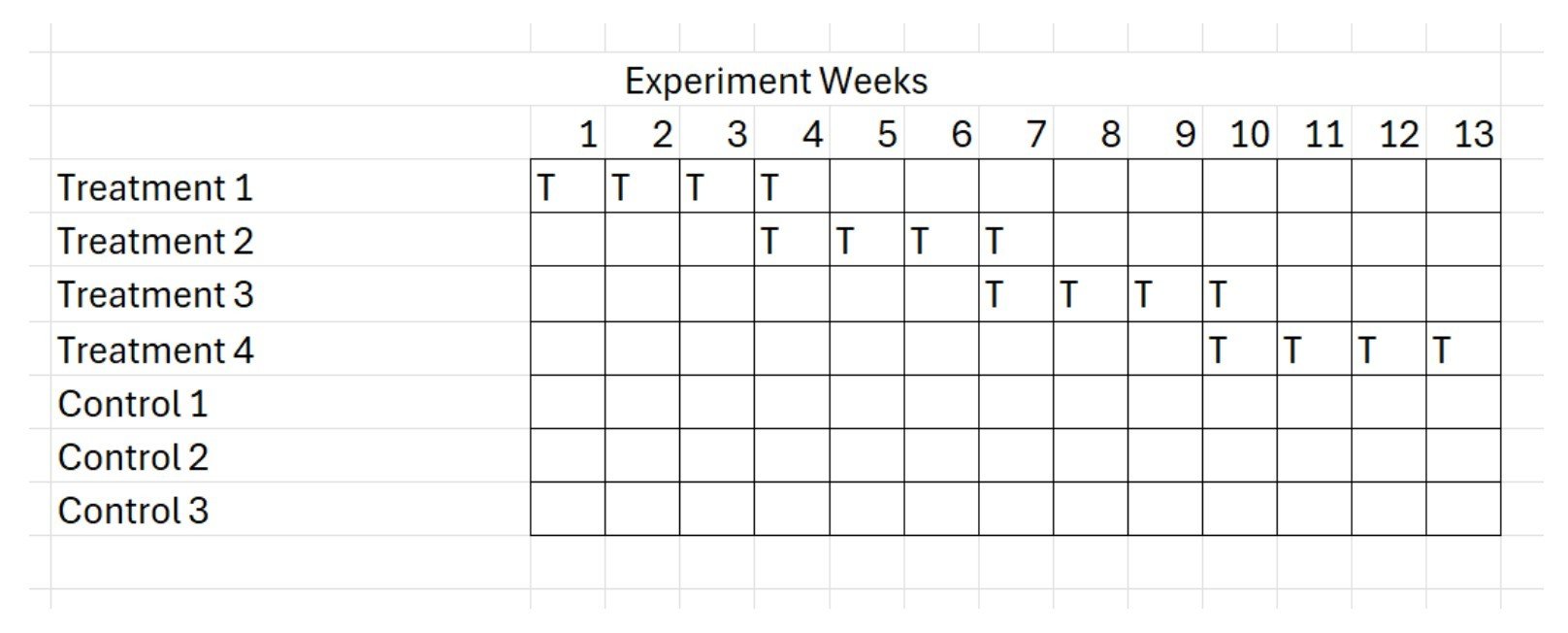
Multi-armed Rolling Stepped Cluster Randomized Trial design, withholding only 18% of media weight
Stratified randomization, statistical normalization of DMA sales rates, and validation of the randomization on covariates such as market share and key demographic variables can be incorporated into the design to strengthen confidence in the results. Ultimately, the best evidence of true sales impact is not a single test but a regular practice of RCTs, in complement with other inference techniques, such as market mix modeling and attribution modeling, so-called unified media measurement, or what we call MPE: models plus experiments.
This kind of geographic experimentation should not be confused with matched market tests (MMT) or its modern counterpart synthetic control methods (SCM). Matched market testing has been used for decades by marketers, and its shortcomings are well understood in the inability for one or a few DMAs in control to replicate the myriad exogenous conditions in the test that could otherwise explain sales differences between markets, such as differing weather conditions, supply chains and competitive mixes, to name a few.
SCM has gained a loyal following in recent years as a newer approach to the same end, using sophisticated statistical methods to improve the comparison of a few test and control geographies. The approach, however, is still fundamentally a quasi-experiment, subject to the inherent limitations of that class of causal inference, namely its reduced ability to control for unobserved confounds, limited generalizability to a national audience and comparatively weaker statistical power, based on a few DMAs compared to all DMAs in the case of large-scale randomized CRTs. While there's ongoing work to improve SCM, I haven't seen any methodological papers claiming SCM to be more reliable than RCT, despite claims to that effect from some advertising measurement practitioners.
As Bouttell et al. (2017) state, "SCM is a valuable addition to the range of approaches for improving causal inference in the evaluation of population level health interventions when a randomized trial is impractical."
Running tests with small, quasi-experimental controls is a choice, not a necessity for most advertising use cases. True, no one dies if an advertiser misallocates budget, as can be the case with health outcomes, where clinical trials (aka RCT) are often mandated for claims of causal effect. But companies lose market share, and marketers lose their jobs, particularly CMOs. When millions or billions in sales are at stake, cutting corners in the pursuit of knowing what works can be ruinous to a brand's performance in a market where outcomes are measurable and competition is zero sum.